

The idea of a Zero Bug Policy can be scary. Especially if it is the first time you have heard that phrase. Those 3 little words carry a huge amount of potential meaning. It can sound impossible to achieve without even truly understanding what it means. When I was reading a post on LinkedIn recently about Bug Counts, it got me thinking again about this topic again. I felt it was time I wrote a blog post about my approach to a zero bug policy.
Before we dive into my approach, I want to share a link to Tanvi Nanda’s post on the Houseful Tech blog. It describes how she successfully introduced a Zero Bug Policy in the Zoopla team at Houseful. The process shares a number of concepts I have used and I highly recommend giving it a read, once you finish reading this one. 😂

What a Zero Bug Policy ISN’T
Lets start with, I don’t like the name Zero Bug Policy. I actually prefer Zero Defect Policy. It may seem like semantaics, but they are different. I really like this definition as it demonstrates the cross over but important difference between a bug and a defect.
A bug is an error or flaw in a software application that causes it to behave unexpectedly or produce incorrect results. On the other hand, a defect is a broader term that encompasses any deviation from a product’s expected behavior or functionality, including software.
Kiruthika Devaraj
Now we have covered that all bugs are defects, but not all defects are bugs it’s important to note that a Zero Defect Policy doesn’t mean your product will never have any defects. It is a commitment towards a way of working and an attitude towards the way that you handle defects when they do arrise.
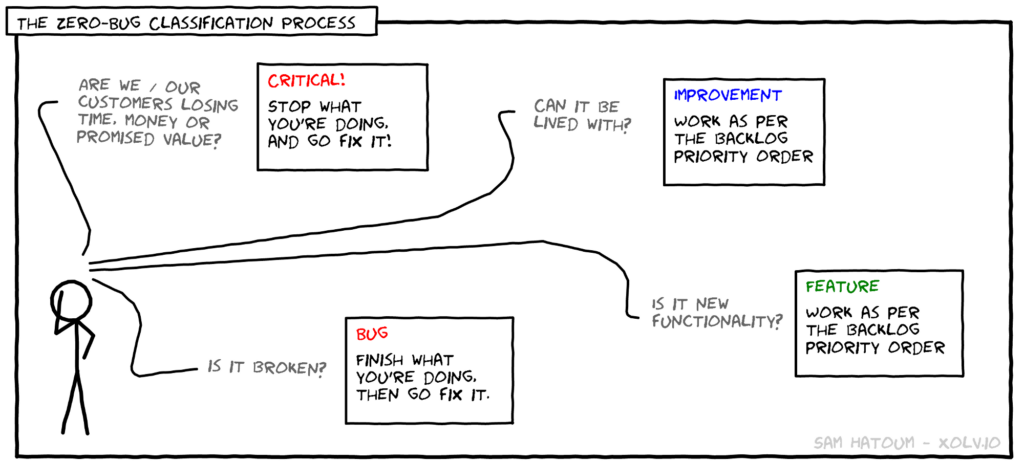
What IS a Zero Defect Policy?
There is not single answer. A Zero Defect Policy will vary in its content and commitment depending on the team and business. As I mentioned earlier, to me a Zero Defect Policy is a commitment made by the team. In this context I mean the broad set of people involved in the delivery of the product. This includes the obvious Software and Quality Engineers , but also Product, Desginers, Leadership etc. Everyone needs to buy into the commitments otherwise it will fail at the first challenge.
This commitment should be recorded, probably as part of a Quality Strategy. It needn’t be a long or overly complex document. But it should contain enough detail that anyone involved in the commitment can understand how it will work. I suggest sections covering Defects Found Before Production, Defects Found In Prodcution, Triaging Defects, Measuring Success. Below I will provide some additional context for each of those sections. As well as my own opinions on what the commitment for that section may look like.
Defects Found Before Production
This section should cover the approach taken to any defects found during test and development. For me this is the simplest to define.
If we find a defect caused by a change, we do not ship that change until the defect is resolved. No if’s, no but’s, no maybes. We never knowingly ship code that introduces a new defect.

Defects Found In Production
Defects found in production are having a direct impact on our users. They should be reviewed as soon as practical. For the next part I will assume that the teams already have good practices in place for incident detection. Therefore any other defects reported are not severe enough to trigger an incident.
For the defects found in production, a ticket should be created that can be triaged by the relevant team. The team will apply a ranking to the ticket and priortise its fix as necessary. This should be a cross discipline process that I will cover more in the Triaging Defects section below.

Triaging Defects
Teams should review reported defects at a regular cadence. Exactly what cadence will depend on your workflow, but as an example I would expect a team working in scrum on 2 week sprints to triage defects at least once per sprint.
The triaging process should involve a cross discipline group that includes representatives of Product, Software Engineering, Quality, and any other SME’s as appropriate to the defects. It does not require the whole team, but you may want to include them the first few times you go through the process.
Meg MacKay has written a fantastic “Guide to Bug refinement” on the Ministry of Testing website that is worth a read for further insights into this process.
Assessing the defect
The pupose of the triaging is to assess:
- User impact – Is it affecting all users or a subset? Is it part of a commonly used area or one that is rarely used?
- Severity – How critical is the defect? Is it preventing a core part of the system from being used, or are there acceptable work arounds?
- Complexity – How difficult will the defect be to resolve? Or what work is requried to understand the root cause before we make an assessment on the resolution?
This will be a discussion across the team members involved in the call. It’s goal is to enable them to come a consensus on a ranking of the defect.
Ranking the defect priority
For ranking I like a simple system consisting of 3 options.
- Fix it now – This type of defect provides a degraded user experience. It is only not an incident because there is an acceptable work around, or a delay in restoring access to this feature is an accepted business risk. Ticket included as part of the next sprint.
- Low priority fix – This defect is providing a degraded user experience, but to a limited user base. Alternatively it may be an edge case that is unlikely to affect many users. Kept in a backlog and reviewed for inclusion each sprint. Any ticket not prioritised after 6 sprints to be considered for changing to Won’t fix.
- Won’t fix – These defects won’t be fixed. They may exist in a legacy system that we are no longer maintaining or are in the process of replacing. The defect may be an annoyance but one that does not prevent the user completing the required actions. Or the complexity to resolve the issue is too high and it is an acceptable business risk to not resolve it.

Measuring Success
How we measure success is an interesting point. It comes down to what the purpose of introducing the Zero Defect Policy was. For me this likely boils down to two points.
- Reduce number of open Defect tickets
- Increase the velocity at which we resolve high priority defects
For each of these it would be possible to measure success using our ticketing system (I nearly wrote Jira, but I know not everyone uses it). Reduction in open defect tickets is easy to measure as its simply a count of open tickets. The increase in velocity at which we resolve high priortity defects may be more diffiult to confirm an improvement if we had no way to categorising defects before. With the introduction of categorising defects, we can now confirm we are meeting the commitment we made in our Zero Defect Policy.
Summary
Every business, and every team is different. Some of what I have said above won’t work for everyone. On top of that, there are always going to be exceptions. The fix for A might introduce B, but introducing B is better than not fixing A, so we ship our change even though we are knowingly introducing a new defect. This comes down to understanding and assessing risk, which is probably a whole other post in its own right.
Have you ever worked with or introduced a Zero Defect Policy? I would love to hear about your experience if you have. Leave a comment below!

Further Reading
If you enjoyed this post, then you may also enjoy my recent post on Why you need to (not) use Story Points. I discuss why I am not a big fan of them, but also how to use them in a way that has worked for many teams I have worked with.
Also, don’t forget to go and check out Tanvi’s post on the Zero bug Policy she introduced at Zoopla.
Subscribe to The Quality Duck
Did you know you can now subscribe to The Quality Duck? Never miss a post by getting them delivered direct to your mailbox.
You may manage your subscription options from your profile.
July 20, 2024 at 7:39 pm
You state ‘Defects Found Before Production’ is the easiest, because of you make a change that introduces a defect, you just fix it. For changes I understand this, but what about new features with defects? What stance do you recommend then because I can’t imagine the stance of fixing everything would work in most places.
July 21, 2024 at 8:21 am
Great question! Above all else I advocate for pragmatism. So what that looks like in your example may vary wildy at different companies with different setups, needs, and pressures.
I see a Zero Defect Policy as an aspirational commitment towards improving how we handle defects. You’ll have noted that even within this approach there are defects that don’t ever get fixed. The main purpose is to provide the structure around handling and fixing of defects, while aspiring towards having zero. The value this brings is an ability to have the clearest view of defects and prioritise fixing the most serious.
Part of this commitment would be to aspire towards never knowlingly releasing a defect. I would hope that in most cases this would be possible. Of course, there will come a time in every business where the pressures to release a new feature out-weigh the potential impact of a known defect.
As someone responsible for Quality, I would want to ensure we have a clear understanding of what the risk of releasing a known defect is and what plan, if any, there is to resolve the issue after release. This infomration then needs to be shared with the relevant stakeholders to ensure they have an accurate understanding of what could go wrong, and the level of risk this could be to the business. Finally, I’d want to make sure that we have a suitable disaster recovery plan in place, so if the worst happens, we have a plan for the fastest possible way to recover. Disaster recovery can take many shapes depending on what it is that is being released. To build further on your example of a new feature, I’d likely be advocating for use of feature flagging and a gradual roll out of the feature so that impact of the defect can be assessed without affecting all users. Or maybe a small change so that when the defect occurs, the user experience is less jarring.
In Quality, we often need to have strong opinions around doing the right thing, but we also need to be problem solvers. This often means finding the acceptable compromise between perfect and getting things done.
March 23, 2026 at 9:56 am
Great insights on backend development technologies! Choosing the right stack truly impacts performance and scalability. Businesses looking to build strong and secure applications should consider expert support.